다음주가 개강? 이건 말도 안된다. 슬슬 종강할 때가 된거 같은데 뭔가 버그가 발생한 듯 ㅇㅇ. 하여튼 어제 있었던 알로하 10주년 기념 대회 출제 후기 쓰러왔음. 이게 알고리즘 놓은 지 꽤 오래된 선배님들도 참여하는 대회라서 난이도 커브 잡기가 너무 어려웠다. 알고리즘을 알아야 풀리는 문제들은 최대한 지양하고, 많이 어려워서도 안되니까 출제가 그리 쉽진 않았음. 또한, 지금 동아리원들 중 잘하는 사람들이 너무 일찍 스코어보드를 얼리는 일이 없도록 해야했기 때문에 그래도 어느정도 난이도는 있어야 했었음. 결과만 보자면, 음.. 적당히 망한(?) 느낌으로 출제가 됐다. 생각보다 난이도를 저평가해서 그런지 알고리즘들을 잘 써야 풀리는 문제는 없었지만, 1시간 30분동안 노솔브가 꽤 있었다. 오프라인 참여해서 풍선 못받으면 좀 슬픈데 ㅠㅠ 미안해요.
문제가 없어요
문제(issue)가 없는 문제(problem)를 출제했다. 그 문제 지문에 적혀있던 내용은 사실을 바탕으로 쓰여졌는데, 사실 우리 대회 11일전에는 문제가 단 하나도 없었다. 그래서 회장님이 ‘문제가 없으면 안돼’ 이러길래 그럼 ‘문제가 있는거네’ 이러면서 말 장난하다가 그걸 그대로 출제를 했다. 단순한 구현 문제고, 지문을 잘 읽으면 한 번에 풀리는 문제다. (지문 읽기 난이도가 젤 어려운듯 ㅋㅋ) 대회 문제 셋에서 가장 쉬운 문제였고, 실제로도 젤 많이 풀렸다. 나름 뿌듯함. 딴 문제들에서 맞왜틀하다가 이 문제 풀어서 1솔권에 들어온 사람들이 꽤 있어서 좋았다.
N명 K분대 남았습니다.
에이펙스 레전드를 하다가 우측상단에 뜨는 인디케이터를 보고 떠올린 문제다. 아마 배틀로얄 중에 몇분대 몇명이 뜨는 게임이면, 음~ 대충 이런 구성으로 팀이 되어있겠네 하는 생각을 해봤을거다. 특히, 에이펙스 레전드에서는 이게 더 중요해서 자연스럽게 생각하다보니 이거 출제해도 괜찮겠네라는 생각이 들어 그대로 출제했다.
원래 처음에는 \(\scriptsize O(NMK)\)가 정해였다. 가만보니, 점화식 계산에 드는 시간을 \(\scriptsize O(NK)\) 또는 \(\scriptsize O(NKlogM)\) 로 줄일 수 있을 것 같았다. 조금 고민을 하다가 안바꿀까? 싶었는데.. 학술부장이 \(\scriptsize O(NMK)\)풀이를 금방 가져오길래 어림없지 ㅋㅋ하고 바로 정해를 \(\scriptsize O(NK)\)로 수정했다. 뭐 그러던 중에 hibye1217님이 dp[i] = 0 (mod M)이면 정해가 틀릴 수 있는 것 때문에 출력 바꾸자고 해서, 원래 불가능한 경우에 -1을 출력하도록 했었는데 그냥 0으로 바꿨다.
나는 DP를 의도하고 출제한 것이긴 했으나, 참여자 중 한 명은 이걸 조합론적 풀이로 풀어서 제출했었다. 중복조합과 조합을 적절히 쓰는 풀이였는데, 아무래도 조합론 문제다 보니까 이게 가능했나보다.
나름 기초적인 DP지만, 그래도 이번 문제 셋에서는 어려운 포지션을 담당했다. 대충 생각한만큼 풀린 것 같고 난이도 포지셔닝이 적절했던 듯.
크게 만들기
갑자기 헉! 하고 떠오른 문제다. 하나 뽑고 나머지 전부 1 감소시키면, 어떻게 뽑아야 뽑은 수의 곱이 최대가 될까? 라는 생각이 그냥 갑자기 떠올랐다. 조금 끄적이다가 왠지 그냥 오름차순으로 곱하면 되는 것 같았는데 난 증명을 못했다. 그래서, 이런 문제 어떠냐고 디코에 올렸는데 hibye1217님이 그냥 바로 뚝딱 하더니 슥하고 삭해서 증명을 가져와줬다. 증명은 조금 배경지식이 없으면 어렵다. 최적의 해를 가정하고 그 순서를 바꿨을 때 바꾼것보다 최적해가 더 커야한다 라는 부등식을 통해 시작한다. 고걸 정리하다 보면, 좀 익숙한 형태가 보이는데 그 부등식을 항상 만족하려면 큰거에 큰걸 곱하면 된다는 사실을 알 수 있다. 정확하게는 재배열 부등식에 의해서 그렇게 되는데, 사실 그 정도의 증명을 대회 시간 내에 하진 않을거라 생각했고 이 문제처럼 직관과 약간의 proof by ac를 통해 해결할 거라 생각했다.
문제에서 시키는것도 그렇고 발상도 약간 codeforce 느낌이라 지문도 그냥 codeforce 감성으로 썼다. 근데, 진짜 어딘가 있을법한 문제이긴 한데 뭐 그냥저냥 무난한 그리디? 수학? 문제였다. 생각보다 proof by ac를 잘 시도안했는지 그냥 바로 보고 넘긴건지는 모르겠지만 예상치보다는 적게 풀린 느낌이다.
그런데 왜 망함?
사실 각자 출제는 잘 했는데 (문제 하나하나 각각 보면 다 괜찮음), 모으고 나서 보니 완전 쉬운 문제.. 흔히 등록 문제라고 하는 문제가 없었다. 제일 쉬운 문제가 내 구현 문제였는데 원랜 그것보다도 더 쉬운게 있어야함. 여튼 그래서 0솔브가 되게 많았다. 상위권을 위한 문제들의 난이도 커브도 살짝 아쉽지만 그래도 이거는 제대로 잡힌 것 같아서 다행이었다. 0솔브가 너무 많았던 점 죄송합니다.. ㅠㅠ
Manim 이라는 수학 애니메이션 visualization을 도와주는 라이브러리가 있길래 한 번 써봤다. 아마 알 사람들은 다 알만한 유튜버 3blue1brown가 개발한 라이브러리다. 왠만한 수학 관련 오브젝트들을 지원하고 사용법도 쉬워서 조금만 배워도 뭘 만들 수 있다. 동아리 학술부장이 ‘컨벡스헐 ㄱ’ 라고 해서 진짜로 만들었다.
Monotone Chain을 이용한 Convex Hull 시각화
사실 Graham’s Scan으로 만드려고 했는데.. 파이썬에 그닥 익숙하지 않아서 커스텀 소트 함수를 제대로 못짰다. 그래서, 타협을 본게 Monotone Chain이다. 아래껍질과 윗껍질을 각각 찾아 합치는 방법이니 그걸 잘 보여주려고 색깔도 다르게 하고 스택에 들어가고 pop하는 과정이 나타나도록 색깔로 구분해서 표현해봤다.
교차하지 않으려면 \(\scriptsize A\)전봇대의 낮은 번호에서부터 볼 때, \(\scriptsize B\)에 연결되어 있는 번호들이 증가하는 모습을 보여야 한다.
연결된 번호가 감소한다면 교차한다는 의미이다.
문제에서 구하는 것은 교차하지 않도록 하기 위해 없애야 하는 최소 전선의 개수이다. 반대로 생각해보자. 가장 긴 증가하는 부분 수열의 길이가 바로 교차하지 않으며 존재할 수 있는 최대 전선의 개수이다. 즉 LIS의 길이를 찾고 (전체 전선 개수 - LIS 길이)을 해주면 정답이다.
이때, \(\scriptsize N\)의 크기가 100으로 작기 때문에, \(\scriptsize O(N^{2})\)짜리 시간복잡도로 LIS 길이를 구해도 된다. 전봇대 \(\scriptsize A\)에 연결된 \(\scriptsize B\) 위치를 차례대로 넣어두고, LIS를 찾으면 된다.
dp[a][b] == dp[a - 1][b]이면, 왼쪽을 감소시키면 된다. 반대로 dp[a][b] == dp[a][b - 1]이면, 오른쪽을 감소시키자. 저 두 경우가 아니면 dp값에 변화가 있어야 했던 부분이니까 둘 다 감소시켜주자. 이런식으로 LCS의 실제값을 구해낼 수 있다. 이해가 안된다면, 직접 dp값을 써보면서 이해하는걸 추천함.
즉, 중간 지점에서 나누어서 합치는 걸로 점화식을 세울 수 있다. \(\scriptsize [i, j]\) 구간의 파일을 합치는 비용의 최솟값은 합쳐진 \(\scriptsize [i, k]\) 파일과 합쳐진 \(\scriptsize [k + 1, j]\) 파일을 합치는 비용의 최소와 같다.
이때, 두 파일을 합치는데 드는 비용은 고정적이다. 따라서, 해당 파트는 prefix-sum 으로 처리할 수 있다. prefix-sum은 간단히 설명하자면, 구간합을 \(\scriptsize O(1)\)에 구할 수 있도록 하는 기법이고 앞에서부터 누적합을 저장한 뒤 적절히 빼는 방식으로 사용할 수 있다. 자세한 설명은 다른 분들이 자세하게 해놨으니 따로 찾아서 공부하는걸 추천드립니다.
하여튼, 저 점화식에 의하면 테이블을 채우는데, \(\scriptsize O(N^{3})\)이니 잘 계산해주면 맞출 수 있다.
(진짜 TMI로 Knuth Optimization(크누스 최적화)라는 것도 적용할 수 있는데.. 이걸 할 줄 알면 이 문제가 \(\scriptsize O(N^{2})\)에 풀리고, 그 문제는 심지어 플래티넘2짜리 문제다. 관심있으면 찾아보세요.)
(단, \(\small \mid xy\mid\)는 \(\small x, y\)의 부호가 서로 다를때만 있는 값이다. 부호가 같거나 0일때는 0의 값을 가짐.)
즉, 구간별로 합칠 때 최소값을 찾아서 전체 문제의 최소값을 찾을 수 있다.
이때, \(\scriptsize x, y\)는 prefix-sum으로 \(\scriptsize O(1)\)에 찾을 수 있으므로 총 시간복잡도 \(\scriptsize O(N^{3})\)에 해결 가능하다.
코드 보기
// 아직 없지롱 우헤헤//*edit : 2022-08-17 02:11 풀이 업데이트*#include<bits/stdc++.h>usingnamespacestd;usingll=longlong;usingpii=pair<int,int>;usingppii=pair<int,pii>;constllINF=1e18;llA[81];lldp[81][81];llpf_sum[81];intN;voidinit(){for(inti=0;i<81;++i)fill(dp[i],dp[i]+81,-INF);for(inti=1;i<=N;++i)pf_sum[i]=pf_sum[i-1]+A[i];}llget_min(intl,intr){ll&ret=dp[l][r];if(ret!=-INF)returnret;if(l==r)returnret=0;ret=0;for(intk=l;k<r;++k){llx=pf_sum[k]-pf_sum[l-1];lly=pf_sum[r]-pf_sum[k];if(x<0&&y>0||x>0&&y<0)ret=min(ret,x*y+get_min(l,k)+get_min(k+1,r));elseret=min(ret,get_min(l,k)+get_min(k+1,r));}returnret;}intmain(){ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);cin>>N;for(inti=1;i<=N;++i)cin>>A[i];init();cout<<get_min(1,N)<<'\n';return0;}
8. 최대 공통 증가 수열 (Gold I)
tag : dp(interval-dp)
풀고 나중에 업데이트 할게요.
//edit : 2022-08-20 15:50 풀이 업데이트
이왜골?
\(\scriptsize O(N^{4})\) 풀이는 아마 떠올릴 수 있을거라 생각합니다.
당연히, \(\scriptsize O(N^{4})\) 풀이는 Naive하게 짜서 그대로 제출하면 시간초과를 받는다.
\(\small dp(i, j) := "A_{i}, B_{j}\) 부터 시작하는 최대 공통 증가 수열 길이” (단, \(\small A_{i} = B_{j}\))
\[\small dp(i, j) := \max_{x > i \wedge y > j} (dp(x, y) + 1)\]
즉, \(\scriptsize O(N^{2})\)개의 부분문제를 계산하는데, \(\scriptsize O(N^{2})\)번 계산을 해야해서 \(\scriptsize O(N^{4})\)이다.
이대로 제출하면, 2%에서 시간초과를 받고 뻗는다.
음.. 그럼 \(\scriptsize N\)을 하나 떼던가 해야 AC를 받을 수 있을거란 생각을 하게 된다. 같은 학술부 hibye1217님은 정직한 \(\scriptsize O(N^{3})\)에 해결했다. 근데, 난 그 방법은 생각하지 못했고, \(\scriptsize O(N^{4})\) 풀이에서 최적화를 통해 문제를 해결했다.
즉, 이제부터 설명할 풀이는 최악의 시간복잡도가 \(\scriptsize O(N^{4})\)이 맞는데, 가지가 많이 쳐내져서 AC를 받을 수 있는..(?) 최적화 풀이이다. \(\scriptsize O(N^{3})\) 풀이가 궁금한 분들은 hibye1217님의 블로그를 참고합시다.
먼저, 모든 \(\scriptsize (x, y)\) 쌍에 대해 값을 가져올 필요가 없다. \(\scriptsize A\)를 기준으로 생각하면, 현재 값보다 큰 값들 중 하나를 골랐을 때, \(\scriptsize B\)에서는 가장 먼저 등장하는 값의 최대 공통 증가 수열 길이를 들고오면 된다.
같은 값이 여러개가 있으면, 가장 앞에서 시작해야 길이가 더 길 것이라 그렇다. 이 정도의 최적화를 해주면 \(\scriptsize O(N^{4})\)이지만, 시간 내에 놀랍게도 돌아간다.
이제 최대 공통 증가 수열을 트래킹해서 같이 출력해주면, 정답을 받을 수 있다. 트래킹하는 방법은 여러가지가 있겠지만 std::map을 사용하면, 어렵지 않게 할 수 있다. 현재 \(\scriptsize (x, y)\) 쌍의 다음 쌍을 저장해놓고 다음 쌍이 없을 떄까지 출력해주면 된다.
자세한건 코드를 참고하세요~
코드 보기
// 아직 없어 우히히//*edit : 2022-08-20 15:50 풀이 업데이트*#include<bits/stdc++.h>usingnamespacestd;usingll=longlong;usingpii=pair<int,int>;usingppii=pair<int,pii>;intdp[501][501];intA[501];intB[501];map<pair<int,int>,pair<int,int>>next_value;intN,M;voidinit(){for(inti=0;i<501;++i)fill(dp[i],dp[i]+501,-1);}intsolve(intx,inty){int&ret=dp[x][y];if(ret!=-1)returnret;ret=1;next_value[{x,y}]={-1,-1};for(inti=x+1;i<=N;++i){if(A[x]>=A[i])continue;for(intj=y+1;j<=M;++j){if(A[i]==B[j]){if(ret<solve(i,j)+1){ret=solve(i,j)+1;next_value[{x,y}]={i,j};}break;}}}returnret;}voidtracking(inta,intb){if(a<=0||b<=0)return;cout<<A[a]<<' ';tracking(next_value[{a,b}].first,next_value[{a,b}].second);}intmain(){ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);cin>>N;for(inti=1;i<=N;++i)cin>>A[i];cin>>M;for(inti=1;i<=M;++i)cin>>B[i];init();intans=0;inta=-1,b=-1;for(inti=1;i<=N;++i){for(intj=1;j<=M;++j){if(A[i]==B[j]){if(ans<solve(i,j)){ans=solve(i,j);a=i;b=j;}break;}}}cout<<ans<<'\n';tracking(a,b);return0;}
9. 팰린드롬 분할 (Gold I)
tag : dp
7, 8 해설과 함께 올라올 예정.
코드는 미리 첨부해놨음!
//edit : 2022-08-20 15:50 풀이 업데이트
갑자기 이런 dp식을 떠올려보자.
\(\small dp(n) := "[0, n]\) 구간에서 최소 팰린드롬 분할 개수”
\[\small dp(n) = \min_{0 \leq k \leq n \wedge \text{[k, n] is pldr}} dp(k - 1) + 1\]
즉, \(\scriptsize [0, n] = [0, k - 1] + [k, n]\) 으로 생각하면, 앞 구간과 뒷 구간으로 나눠 생각할 수 있는데, 뒷 구간이 팰린드롬인지 검사하고 앞에서 최소 개수를 얻어오는 것이다. 이때, \(\scriptsize k = 0\)이면 앞 구간 팰린드롬 분할 수가 0인걸로 생각하면 된다.
팰린드롬 전처리는 \(\scriptsize O(N^{2})\)에 할 수 있다. \(\scriptsize N = 2500\)이므로, 시간 내에 전처리 할 수 있다. (스트링 길이 생각안하고, 나이브하게 짜도 시간 내에 돌아감.)
이 점화식을 그대로 짜면 맞출 수 있다. 아마 dp식을 2차원으로만 생각하고 있었다면, 꽤 헤맬 수 있는 문제였다.
코드 보기
#include<iostream>
#include<vector>
#include<string>
#define MAX 2500
usingnamespacestd;intdp[MAX];boolisPldr[MAX][MAX];stringstr;voidisPalindrome(string&str,inta,intb){for(inti=0;i<=(b-a)/2;++i){if(str[a+i]!=str[b-i]){isPldr[a][b]=false;return;}}isPldr[a][b]=true;}intsolve(string&str,intn){if(n<0)return0;int&ret=dp[n];if(ret!=-1)returnret;ret=MAX+1;for(intk=0;k<=n;++k){if(isPldr[k][n])ret=min(ret,1+solve(str,k-1));}returnret;}intmain(){ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);for(inti=0;i<MAX;++i)dp[i]=-1;//initcin>>str;for(inti=0;i<(int)str.size();++i){for(intj=i;j<(int)str.size();++j){isPalindrome(str,i,j);}}cout<<solve(str,(int)str.size()-1);return0;}
즉, 다른 두 스트링을 합칠 때, 합쳐지는 그 부분이 반복이 된다. 처음엔 \(\scriptsize F(N - 1)\)과 \(\scriptsize F(N - 2)\)이 합쳐지고, 그 다음 스트링에서는 \(\scriptsize F(N - 2)\)와 \(\scriptsize F(N - 1)\)이 합쳐진다. 이게 쭉 반복되기 때문에, 우리는 \(\scriptsize F(N - 1), F(N - 2)\)을 합칠 때 발생하는 추가적인 매칭과 \(\scriptsize F(N - 2), F(N - 1)\)을 합칠 때 발생하는 추가적인 매칭을 구하면 문제를 풀 수 있다.
왼쪽 스트링의 오른쪽 끝에서부터 \(\scriptsize \mid p\mid - 1\)개를 가져오고 오른쪽 스트링의 왼쪽 끝에서부터 \(\scriptsize \mid p\mid - 1\)개를 가져와서 합치면, 합쳐져서 발생하는 모든 스트링을 검사할 수 있게 된다.
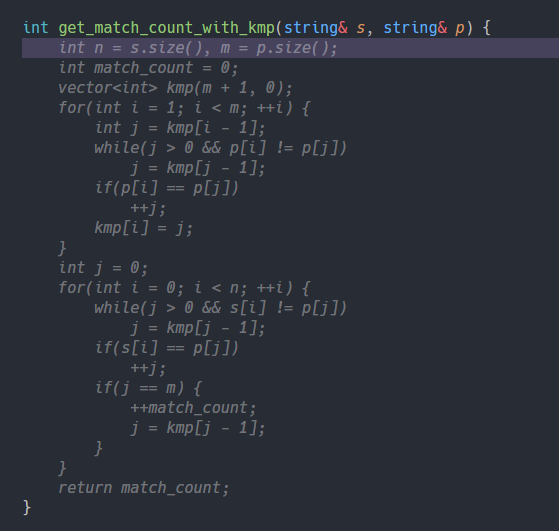
개수를 구하는 방법은 해싱이든 KMP든 \(\scriptsize O(N + M)\)에 매칭을 할 수 있는 알고리즘으로 하면 된다. 나는 KMP로 했다.
\(\scriptsize p\)의 길이보다 커지는 최초의 \(\scriptsize N\)을 찾아서 저걸 해주면 되는데, \(\scriptsize p\)가 100,000이니까 대충 30정도를 가져오면 된다. 30이전까지는 Naive하게 KMP를 돌려서 dp 배열을 채워주고, 30부터는 위의 방법을 적용시켜서 dp 배열을 채워나가면 된다.
두가지의 풀이가 있다. 하나는 DFS를 하는 방법이고, 하나는 플로이드-워샬 알고리즘을 사용하는 방법이다. 본인은 DFS 풀이가 더 쉽다고 생각하기에 DFS 풀이만 소개하도록 하겠습니다. 사실상 뜯어보면 같은 풀이고 시간복잡도도 \(\scriptsize O(N^{3})\) 동일하니 편한걸로 푸시면 됩니다.
먼저, \(\scriptsize a \rightarrow b :=\) “\(\scriptsize a\)가 \(\scriptsize b\)보다 키가 작다.” 이므로, 어떤 노드를 잡고 해당 노드를 시작점으로 DFS를 돌려 방문 가능한 노드들은 시작 노드보다 키가 큰 노드들이다. 반대로, 간선 방향이 반대로된 그래프가 있다고 해보자. 해당 그래프에서는 방향 간선이 반대의 의미를 갖는다. 즉, \(\scriptsize a \rightarrow b :=\) “\(\scriptsize a\)가 \(\scriptsize b\)보다 키가 크다.” 이므로, 이 그래프에서 DFS를 돌리면 키가 작은 노드들에 대한 정보를 얻을 수 있다.
어떤 특정 노드가 몇 번째로 키가 큰 건지 알려면 정방향 그래프, 역방향 그래프에서 방문 가능한 노드들을 모았을 때, 전부 모아져야 한다. 쉽게 말하자면, (자기보다 키가 큰 사람의 수 + 자기보다 키가 작은 사람의 수) = (자신을 제외한 모든 노드의 개수) 이니 모든 노드에 방문 가능해야하다. 그래야지 자신의 위치가 어딘지 확정된다.
문제 첫번째 예제에서 5번을 시작점으로 정방향 그래프 DFS를 수행하면, 2, 4, 6번에 방문 가능하다. 역방향 그래프 DFS를 수행하면, 1번에 방문 가능하다. 이때, 3번에는 방문이 불가능하므로 5번 노드는 몇번째인지 알지 못한다. 반면, 4번 노드는 모두 방문 가능하기 때문에 자신의 위치를 확정시킬 수 있다.
모든 노드들에 대해 이 방법을 그대로 적용시켜 DFS를 수행해주면 된다. 정방향 DFS / 역방향 DFS를 해주면 되고 적당히 잘 처리해주면 AC를 받을 수 있다.
플로이드-워샬 풀이도 비슷하다. 플로이드-워샬 알고리즘을 수행하면 all to all 최단 거리 정보를 얻을 수 있는데, 특정 노드로부터 다른 모든 노드들까지 거리 정보가 저장된다면 위치 확정이 된다는 의미이니 똑같이 풀 수 있다.
은근히 문제가 복잡하기 때문에 잘 읽어줘야 한다. 요약하면, \(\scriptsize g-h\) 교차로를 지나면서 최단거리로 도달할 수 있는 후보노드들을 출력해주면 된다. 가질 수 있는 경로를 대략 표현해보면 아래와 같다.
\[s \rightarrow g \rightarrow h \rightarrow t\]
\[s \rightarrow h \rightarrow g \rightarrow t\]
어느 정점을 먼저 방문하느냐에 따라 이렇게 두가지 케이스만 존재한다.
그럼, 알아야하는 정보는 \(\scriptsize s \rightarrow g\) 최단경로, \(\scriptsize h \rightarrow t\) 최단 경로, \(\scriptsize s \rightarrow h\) 최단경로, \(\scriptsize g \rightarrow t\) 최단 경로다.
이는 \(\scriptsize s, g, h\)를 시작으로 하는 다익스트라를 각각 돌려 얻어낼 수 있다. 후보 \(\scriptsize t\)에 대해 계속 경로를 만들어보며 해당 경로의 길이가 \(\scriptsize s\)로부터 \(\scriptsize t\)까지의 거리와 같은지 확인하는 걸로 가능한 후보임을 알 수 있다.
\(\scriptsize T\)와 가까워진다는 조건이 무엇을 의미할까? 간선을 타고 이동했을 때, \(\scriptsize T\)까지 최단거리값이 짧아진다는 의미이다. 그럼 슨생님.. 모든 노드로부터 \(\scriptsize T\)까지 거리가 필요한 거 아닌가요? 물론 그렇게 생각할 수도 있다. 그러나, 반대로 생각해서 \(\scriptsize T\)부터 모든 노드의 거리를 아는 방법이 더 쉽고 더 빠르다. 그러니 우리는 그렇게 생각하도록 합시다.
\(\scriptsize T\)부터 모든 노드까지의 거리는 다익스트라 알고리즘 한번이면 구할 수 있다. 이제, 그럼 \(\scriptsize T\)와 가까워지며 이동할 수 있게는 되었다. 어떤 노드 \(\scriptsize u\)에서 다른 노드 \(\scriptsize v\)로 이동할 때, 현재 \(\scriptsize dist(u) > dist(v)\)인지 확인하고 이동하면 되기 때문이다.
\(\scriptsize T\)랑 가까워지는곳으로 이동하는 이 조건만으로도 그래프가 트리로 고정이 되는 것 같은데, 본인은 왜 그런지 잘 이해가 안됐기에.. 일단 해당 조건을 만족하도록 그래프를 새로 만드는 과정을 거쳤다. 그런 이후 위상 정렬 + DAG dp로 문제를 해결했다.
이제, 위상정렬을 수행하면서 dp를 해주면 되니까 답을 구할 수 있다. dp를 하고나면, 2번 노드에 저장된 카운트 값을 출력해주면 된다.
.
.
.
.
.
.
인데.. 위상정렬 필요없이 최단거리 정보를 활용한 트리 dp로 풀리는 모양이다. 난 트리로 안 생겼을 수 있다고 생각해서 위상정렬을 넣었는데 왜 그런지 아시는 분은 댓글좀 남겨주세요. 하여튼, 이런식으로 풀면 플래5 정도 난이도를 가진 문제라고 생각한다. 쉽진 않은 문제이니 천천히 풀어보시길 바랍니다.
누가봐도 귀찮은 구현 시뮬레이션 문제다. 풀 마음이 아직 안생겨서.. 풀고나서.. 풀이 올리도록 하겠습니다 ㅎㅎ
edit : 2022/08/04 22시 문제 풀어왔습니다
다익스트라를 잘 활용해서 풀 수 있는 좀 많이많이 빡센 구현 문제다. 본인은 다 풀어놓고, \(\scriptsize 500 \cdot 500 = 25000\) 으로 잘못생각해서 한 4시간 날렸는데, \(\scriptsize 500 \cdot 500 / 4 = 62500\) 이니 알아두길 바랍니다.. (나만 산수 못해) 여튼 배열 크기 잘못 잡았더니 WA받고(RE를 띄워줘야 하는데 안떴음) n시간 날려서 억울함.
기본적으로, \(\scriptsize H \times W\) 사이즈의 맵에서 유닛들을 조건에 맞게 옮겨주는 문제다. 조건이 좀 많아서 구현이 어지러울 뿐이다. 중요한 조건을 정리하자면, 다음과 같다.
각 유닛은 자신의 이동력보다 작거나 같은 거리만큼 움직일 수 있다.
다른 세력의 유닛이 인접하면 교전이 시작되니 피해서 움직여야 한다.
다만, 2번의 경우 도착하는 위치가 교전이 시작될 위치면 예외로 치자.
교전을 하고 있는 상태에서 약진을 통해 해당 위치를 벗어날 수 있다.
이동할 곳이 유닛이 있거나 -1의 험준도를 가지는 위치면 불가능하다.
이걸 잘 구현해주면 된다. 말만 쉽지 오래걸린다. 먼저, 1번 조건은 다익스트라 알고리즘으로 해결할 수 있다. 각 노드별로 가중치가 설정되어 있는데, 이를 이용해 다익스트라를 돌려 작은 가중치를 따라가는 경로로 이동하는게 항상 이득이다. 헉, 그런데 이렇게 \(\scriptsize T\)번 다익스트라를 돌리면 \(\scriptsize O(T \cdot HWlog(HW))\)아닌가요? 유의미한 지적이다. 그런데, 문제 조건에 지형의 험준도는 0이 될 수 없고 항상 1 ~ 3까지의 값을 가진다고 하네요. 이때, 각 유닛별 최대 이동력은 20이기 때문에 상하좌우 20칸 내부 범위에서만 다익스트라 알고리즘이 수행됨을 알 수 있다!
그렇기 때문에, 매번 다익스트라를 돌린다고 하더라도 충분히 시간내에 코드가 돌아갈 것임을 짐작할 수 있다. 2번의 구현은 사람마다 다를 수 있다. 나는 각 세력별로 유닛이 놓인 위치와 해당 위치의 상하좌우에 따로 표시를 해서 표시된 구간에 들어서지 못하도록 구현했다. 좌표 이동을 하면, 원래 위치에 표시된 값들은 다시 지워주고, 이동한 위치에 새로 표시해주면 된다. 아래 코드에서 party_0, party_1이 그 역할을 하는 배열이다.
3번은 적당히 다익스트라를 수행하면서 예외로 처리해주자. 내가 구현한 방식대로 구현하게 된다면 4번은 신경쓰지 않아도 된다. 다익스트라에 쓰이는 시간을 아끼기 위해서, 최단거리 탐색에 앞서서 갈려는 좌표가 -1이거나 유닛이 이미 존재하는지 먼저 체크하자. 이게 5번의 처리 방법이었다.
요렇게만 구현하면 풀릴 줄 알았지만!!! 세상은 차가운 곳이었다..
조금 최적화를 해줘야 시간 내에 통과된다. 구현에 따라 최적화가 필요없을 수 있지만, 다익스트라를 돌릴 때 이동할 좌표가 힙에서 나오면, 바로 함수를 종료해주도록 하자. 이 정도의 최적화를 해주면 시간 내에 풀이가 통과된다.
다익스트라 부분만 따로 보자.
// 다익스트라 구현 파트// 초기 좌표 거리값 0으로 설정dist[y][x]=0;pq.push({0,y,x});while(!pq.empty()){// 현재 좌표 받아오기intcur_y=pq.top().y;intcur_x=pq.top().x;intcur_dist=pq.top().dist;pq.pop();// 만약, 이미 이동할 좌표에 도달했으면 함수 종료if(cur_y==a&&cur_x==b)returntrue;if(cur_dist>dist[cur_y][cur_x])continue;for(inti=0;i<4;++i){// 다음 좌표 받아오기intnext_y=cur_y+dy[i];intnext_x=cur_x+dx[i];// 다음 좌표가 내부인지 검사if(next_x<0||next_x>=W||next_y<0||next_y>=H)continue;// 해당 좌표 험준도 값이 -1이 아니어야 함.if(r[m[next_y][next_x]]==-1)continue;// 해당 좌표에 다른 세력이 영향을 미칠 수 있는 지 체크해줘야 함. (인접한 곳인지 체크)if(party[next_y][next_x]&&!(next_y==a&&next_x==b))continue;intnext_dist=cur_dist+r[m[next_y][next_x]];// 현재 거리값이 더 작고, 이동력보다 거리를 덜 이동했을 때 힙에 삽입if(next_dist<dist[next_y][next_x]&&next_dist<=u[unit_n].m){dist[next_y][next_x]=next_dist;pq.push({next_dist,next_y,next_x});}}}
구현을 보면 알겠지만, 문제에서 시키는 조건을 잘 넣어주면 성공적으로 다익스트라를 수행할 수 있다. 자세한 구현은 아래 코드를 참고하자
코드 보기
// 아직 없어.. 우히히// edit : 2022 / 08 / 04// 이제 있어! 헤헤#pragma GCC optimize ("O3")
#pragma GCC optimize ("Ofast")
#pragma GCC optimize ("unroll-loops")
#pragma GCC target("sse,sse2,sse3,ssse3,sse4,avx,avx2")
#include<bits/stdc++.h>usingnamespacestd;usingll=longlong;usingpii=pair<int,int>;usingppii=pair<int,pii>;structunit{intm,party,y,x;};intN,H,W;// N : the number of terrain types, H : row, W : columnintm[501][501];// mapintr[10];// terrain valuesunitu[70707];intparty_0[501][501],party_1[501][501];intunit_place[501][501];intdist[501][501];intdy[4]={0,1,0,-1};intdx[4]={1,0,-1,0};constintINF=1e9;voidmark_party(intt,inta,intb,boolplus){intdelta=plus?1:-1;auto&party=(t==0)?party_0:party_1;party[a][b]+=delta;unit_place[a][b]+=delta;for(inti=0;i<4;++i){intny=a+dy[i];intnx=b+dx[i];if(nx<0||nx>=W||ny<0||ny>=H)continue;party[ny][nx]+=delta;}}booldijkstra(intunit_n,inta,intb){inty=u[unit_n].y;intx=u[unit_n].x;auto&party=(u[unit_n].party==0)?party_1:party_0;structnode{intdist,y,x;booloperator<(constnode&x)const{returndist>x.dist;}booloperator>(constnode&x)const{returndist<x.dist;}};priority_queue<node,vector<node>,greater<node>>pq;for(inti=0;i<501;++i)fill(dist[i],dist[i]+501,INF);dist[y][x]=0;pq.push({0,y,x});while(!pq.empty()){intcur_y=pq.top().y;intcur_x=pq.top().x;intcur_dist=pq.top().dist;pq.pop();if(cur_y==a&&cur_x==b)returntrue;if(cur_dist>dist[cur_y][cur_x])continue;for(inti=0;i<4;++i){intnext_y=cur_y+dy[i];intnext_x=cur_x+dx[i];if(next_x<0||next_x>=W||next_y<0||next_y>=H)continue;if(r[m[next_y][next_x]]==-1)continue;if(party[next_y][next_x]&&!(next_y==a&&next_x==b))continue;intnext_dist=cur_dist+r[m[next_y][next_x]];if(next_dist<dist[next_y][next_x]&&next_dist<=u[unit_n].m){dist[next_y][next_x]=next_dist;pq.push({next_dist,next_y,next_x});}}}returnfalse;}voidmove_unit(intunit_n,inta,intb){if(r[m[a][b]]==-1)return;if(unit_place[a][b])return;if(dijkstra(unit_n,a,b)){mark_party(u[unit_n].party,u[unit_n].y,u[unit_n].x,false);mark_party(u[unit_n].party,a,b,true);u[unit_n].y=a,u[unit_n].x=b;}}intmain(){ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);cin>>N>>H>>W;for(inty=0;y<H;++y){for(intx=0;x<W;++x){cin>>m[y][x];}}for(inti=1;i<=N;++i)cin>>r[i];intM;cin>>M;for(inti=1;i<=M;++i){intm,t,a,b;cin>>m>>t>>a>>b;u[i]={m,t,a,b};mark_party(t,a,b,true);}intK;cin>>K;while(K-->0){intu,a,b;cin>>u>>a>>b;move_unit(u,a,b);}for(inti=1;i<=M;++i)cout<<u[i].y<<' '<<u[i].x<<'\n';return0;}
9. K번째 최단경로 찾기 (Platinum IV)
tag : dijkstra, priority_queue
웰노운류의 문제다. 모르면 맞는..
노드 개수만큼의 힙(max)을 만들어주고, 기본적으로는 다익스트라를 수행할거에요.
각자 노드마다 자신의 힙이 있고, 힙에는 해당 노드까지의 거리정보가 쌓인다. 이제 힙 크기가 \(\scriptsize K\)개가 되도록 관리 해주면 된다. 힙 크기가 \(\scriptsize K\)보다 작으면 거리정보를 push해주고, 힙 크기가 \(\scriptsize K\)이면 top과 비교해서 작을 때, top을 pop하고 거리 정보를 push해주면 된다.
이렇게 관리하면, 다익스트라 알고리즘이 모두 수행되었을 떄, 각 노드별 힙의 top에는 \(\scriptsize K\)번째로 긴 최단경로의 길이가 저장된다. 이때, 힙의 크기가 \(\scriptsize K\)보다 작으면 그것은 \(\scriptsize K\)번째 최단 경로가 없다는 뜻이니 -1을 출력하면 된다.
edit : 2022/08/05 hibye1217님이 너무 좋은 문제를 들고오셔서 set에 추가했습니다.
tag : floyd-warshall, offline-query
선린은 낭만 있는 고등학교네요.. 아무튼 진짜 야무진 플로이드-워샬 알고리즘을 쓰는 문제다. 플로이드-워샬 알고리즘은 근본적으로 DP이다. 이 DP에 대해 정확한 이해를 하고 있으면 풀 수 있는 문제다.
먼저, 반딧불이 상수 \(\scriptsize C\)를 가지고 있고 \(\scriptsize 2^{C}\) 방울 이상 마시면 날아가지 못한다고 한다. 이는 경로상에 출발지와 도착지를 제외하고는 노드 번호가 \(\scriptsize C\)이상이 되면 안된다는 의미이다. 수학으로 설명하는게 깔끔하지만, 직관적인 이해가 문제 푸는데는 더 도움이 되기 때문에 왜 그렇게 해야하는지 러프하게 설명해보겠다.
경로상의 이슬을 모은 값은 \(\scriptsize \sum_{x} 2^{x}\) 이다. 이 값이 \(\scriptsize 2^{C}\) 보다 작아야 이동이 가능하다. 이진수 표현법으로 한 번 표현해보자.
\(\scriptsize 2^{C}\)를 넘기지 않으려면, \(\scriptsize C\)번째 자리 미만에서만 비트가 켜져 있으면 된다. 켜진 비트 하나하나가 \(\scriptsize 2^{x}\)와 같기 때문에 그렇다. 즉, \(\scriptsize C\)번 보다 작은 노드들로 경로가 구성되어 있어야 조건을 만족할 수 있다.
조건 하나를 드디어 해석했다. 쿼리 \(\scriptsize (C, s, e)\)는 \(\scriptsize C\)번 미만으로 구성된 경로에서 최단 경로를 찾으면 된다!
그런데, 문제는 \(\scriptsize C\)가 여러개가 주어지고 \(\scriptsize (s, e)\) 조합이 매우 많다는 점이다. 그럼, all to all 최단 경로 알고리즘이 필요하고, 각 \(\scriptsize C\)마다 뭔가 달라져야 할 것 같다.
우리가 아는 all to all 최단 경로 알고리즘은 플로이드-워샬 알고리즘이다. 이걸 활용하면 문제를 풀 수 있다. 해답은 플로이드-워샬의 dp 정의식에 있었다. dp 정의식을 공부해보자.
\(\small dp(i, j, k) := "i\) 에서 \(\small j\)까지 \(\small [1, 2, ..., k]\) 꼭짓점을 경유지로 삼을 때, 최단거리”
라고 정의하자. 어떤 최단거리는 \(\scriptsize k\)를 경유지로 삼는 최단거리와 그렇지 않은 최단거리 중 하나에 무조건 속한다. 따라서, 다음과 같은 dp 관계식을 유도할 수 있다.
\[\small dp(i, j, k) = \min(dp(i, j, k - 1), dp(i, k, k - 1) + dp(k, j, k - 1))\]
보통 별 생각 없이 쓰는 세제곱 짜리 반복문에 이런 내용이 담겨있다. dp 정의식을 잘 생각해보면, 요걸 이용해서 \(\scriptsize C\)번 노드 미만으로 구성된 최단 경로 값을 구해낼 수 있다.
여기서, 풀이가 둘로 나뉜다.
dp 식 그대로 해결하기
오프라인 쿼리로 해결하기
본인은 2번으로 해결했으니, 2번으로 설명해보겠습니다. (메모리 덜 먹고 좀 더 빠른듯)
먼저, 오프라인 쿼리란 질의가 들어온 것을 그때그때 처리하지 않고, 질의들을 모아뒀다가 나중에 처리하는 기법을 의미한다. 반대로 온라인 쿼리는 질의가 들어올 때마다 처리해주는 기법이다.
쿼리들을 모조리 다 받아주자. 그런 뒤 쿼리들을 \(\scriptsize C\)에 대해 오름차순으로 정렬해주고, 이제 쿼리를 하나식 꺼내서 dp식의 \(\scriptsize k\)값을 \(\scriptsize C\)미만 까지 업데이트 시켜주면 된다. 그런 뒤 처리한 결과를 이용해 따로 정답 배열에 집어 넣자. 이걸 모든 쿼리에 해주면 답을 구할 수 있다.