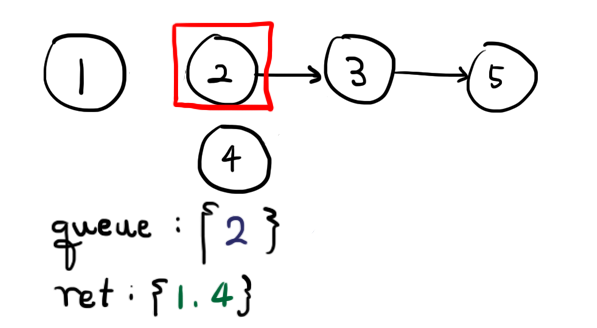
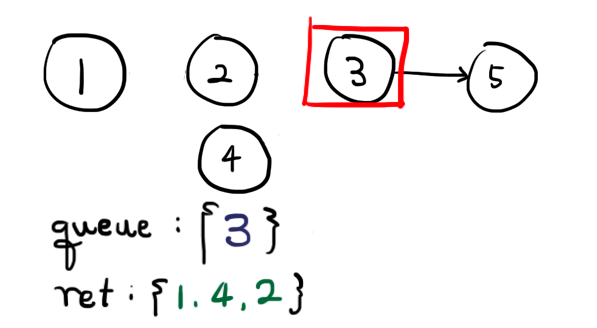
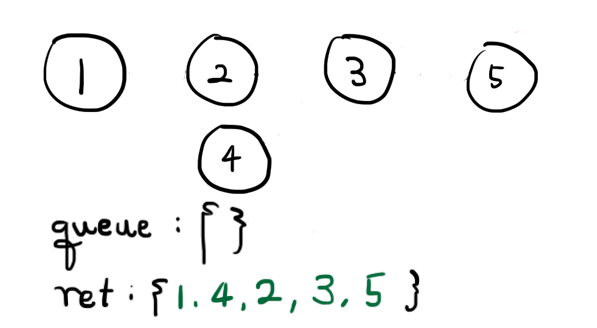제 6회 HCPC Beginner Division PS일지
08 Nov 2021제 6회 HCPC Beginner Division
11월 말에 HCPC가 있다고해서 연습좀 해볼겸 이미 나온 기출 셋을 한 번 돌아보기로 했다. 지금까지(11-08, 17시) 1문제 TLE고 나머진 AC를 받았다. 예전부터 DP가 넘 어려웠는데 아직도 그런거 같다. 왜냐면 TLE때문에 못푼 단 하나의 문제가 DP임..ㅋㅋ 여튼 DP 공부좀 열심히 해야겠다는 생각이 드는 그런 셋이었다.
A번 : 과제는 끝나지 않아! / BOJ 17952
Tier : Silver III
설명 보기
간단한 구현 문제이다. 문제에서 시키는대로 구현하면 AC를 받을 수 있다. 이때, 이전회차에 그만둔 과제를 이어서 해야하니 선입후출 특징을 가지는 자료구조가 있으면 편리하다. 그게 딱 스택에 해당하니, 스택을 사용해서 문제에 나와있는것을 그대로 구현해주면 된다.
코드 보기
int main() {
int ret = 0;
int N; cin >> N;
stack<pair<int, int>> stk;
int score = 0, time = 0;
for(int i = 0; i < N; ++i) {
int cmd; cin >> cmd;
if(cmd == 1) {
if(time > 0) stk.push({score, time});
cin >> score >> time;
if(--time == 0) {
ret += score;
if(!stk.empty()) {
score = stk.top().first;
time = stk.top().second;
stk.pop();
}
}
}
else {
if(--time == 0) {
ret += score;
if(!stk.empty()) {
score = stk.top().first;
time = stk.top().second;
stk.pop();
}
}
}
}
cout << ret;
return 0;
}
B번 : 흩날리는 시험지 속에서 내 평점이 느껴진거야 / BOJ 17951
Tier : Gold IV
설명 보기
그룹으로 나눠서 각 그룹별 합의 최소값이 최대가 되어야하도록 만드는 문제이다. 난 처음에 생각없이 전체 합 / 그룹 수 = 평균이라는 식을 써서 이 평균값보다 커지는 최초의 원소에서 끊기도록 그룹을 나눴는데.. 뭐 증명도 없이 풀었기에 당연하게도 WA. 끝 그룹에서 극단적인 case가 나올수도 있고 여러모로 반례가 많은 풀이이니 당연히 안된다. 여튼, 그래서 좀 생각을 해보니 이분탐색으로 값을 찾아주면 되는거 아닌가 싶어 그렇게 코드를 짰다. 각 그룹의 합이 최소 mid보다 크도록 해서 그룹을 나누고, 그 다음 나눠진 그룹의 수로 range를 줄여나가는 식으로 하면, count >= 그룹의 수 일때, 답의 후보가 발생한다. 그 때마다 값을 갱신하면, 마지막에 저장된 값이 곧 답이된다. 즉, 파라메트릭 서치로 요로로콤 해결할 수 있는 문제였다.
코드 보기
#include <iostream>
#include <cmath>
#include <vector>
using namespace std;
int solve(vector<int>& seq, int K) {
int r = 20 * 1e5;
int l = 1;
int ret = -1;
while(l <= r) {
int partition = 0;
int mid = (l + r) / 2;
int cnt = 0;
for(int i = 0; i < (int)seq.size(); ++i) {
partition += seq[i];
if(partition >= mid) {
cnt++;
partition = 0;
}
}
if(cnt >= K) {
ret = mid;
l = mid + 1;
}
else r = mid - 1;
}
return ret;
}
int main() {
int N, K; cin >> N >> K;
vector<int> seq(N);
for(int i = 0; i < N; ++i) cin >> seq[i];
cout << solve(seq, K);
return 0;
}
C번 : Drop The Byte! / BOJ 17949
Tier : Bronze I
설명 보기
문제에서 시키는대로 하면 된다. char이면 2자리, int면 8자리, long_long이면 16자리씩 string을 끊어주고, 그 끊어준 string을 10진수로 convert하면 AC. 뭔가 16진수 string -> 10진수 string으로 바꿔주는게 있을 법 한데, 나는 그냥 map을 써서 직접 변환시켜주는 식으로 풀었다. 그러나, 난 처음에 이거 TLE받았는데, 처음엔 그냥 진짜 substr로 string을 잘랐기 때문에 그랬다. 빠르게 하기 위해서 인덱스를 저장해두고 자른 효과를 주는 식으로 바꾸었더니 AC.
코드 보기
#include <iostream>
#include <map>
#include <string>
using namespace std;
map<char, long long> convert = { {'0', 0}, {'1', 1}, {'2', 2}, {'3', 3}, {'4', 4}, {'5', 5}, {'6', 6}, {'7', 7}, {'8', 8}, {'9', 9}, {'a', 10}, {'b', 11}, {'c', 12}, {'d', 13}, {'e', 14}, {'f', 15} };
long long calc(string& s, int idx, int sz) {
long long ret = 0;
long long size = 1;
for(int i = idx + sz - 1; i >= idx; --i) {
ret += convert[s[i]] * size;
size *= 16;
}
return ret;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
string str; cin >> str;
int N; cin >> N;
int idx = 0;
for(int i = 0; i < N; ++i) {
string cmd; cin >> cmd;
if(cmd == "char") {
cout << calc(str, idx, 2) << " ";
idx += 2;
}
else if(cmd == "int") {
cout << calc(str, idx, 8) << " ";
idx += 8;
}
else {
cout << calc(str, idx, 16) << " ";
idx += 16;
}
}
return 0;
}
D번 : 퐁당퐁당 1 / BOJ 17944
Tier : Bronze III
설명 보기
간단한 문제다. 뭐 잡다한 설명이 많은데, 그냥 1 2 3 … 2n - 1 2n 2n -1 … 3 2 1 2 3 … 이런 수열의 특정 항을 구하는 문제로 정리해볼 수 있겠다. 수열 생긴 꼴을 보면 음 뭔가 모듈러로 \(\scriptsize O(1)\)만에 특정번째 항을 구해낼 수 있을 것 같다. 일반항을 찾다보니까 좀 껄끄로워서.. ㅋㅋ 아예 찾아가는식으로 구현했다 그냥. 그래서 아래 코드는 복잡도가 \(\scriptsize O(T)\)이다.
코드 보기
#include <iostream>
using namespace std;
int main() {
int N, T; cin >> N >> T;
int ret = 0;
bool flag = false;
for(int i = 0; i < T; ++i) {
if(ret == 2 * N) flag = true;
else if(ret == 1) flag = false;
if(flag) ret--;
else ret++;
}
cout << ret;
return 0;
}
E번 : 뜨끈한 돼지국밥 / BOJ 17948
Tier : Platinum III
설명 보기
아직 TLE라 해결하지 못했지만, 중간 풀이를 남겨보려 한다.
2021-11-08-17시 기준으로 \(\scriptsize O(n ^ {4})\) 정도의 DP 풀이를 만들어낼 수 있었다. 이 문제를 해결하기 위해서는 \(\scriptsize O(n ^ {2})\) 까지는 줄여야해서.. 아직 터무니없이 복잡도가 높다. 먼저 \(\scriptsize cost(count, x) = "count번째 국밥집을 x주소에 놓았을 때 최소 비용"\) 이라고 정의했다. 그럼, \(\scriptsize cost(count, x) = min(cost(count, x), cost(count - 1, k) + newSummation + m) (k < x)\)이라고 할 수 있다. 이때, newSummation은 x주소에 국밥집을 놓으면서 변화하는 거리비용을 의미한다. 즉, 주소 k 국밥집보다 주소 x 국밥집에 더 가까우면 원래 있던 값을 빼줘야하니 빼고, 수정된값으로 바꿔놓아야하니 그 값들을 모두 합친게 newSummation이다. count가 하나 증가할때마다 m이 하나씩 증가하니 m도 하나 증가시켜주면 된다.
이런식으로 구하면 cost(count, x) 테이블을 채우는데에 \(\scriptsize O(n ^ {3})\)이고, newSummation을 구하는데에 \(\scriptsize O(n)\)이라 \(\scriptsize O(n ^ {4})\)라 TLE이다. 그래서 아직까지 실패했으나, 그래도 풀이를 남기는게 의미있을듯 싶어 남겨본다.
코드 보기
#include <iostream>
#include <vector>
#include <cmath>
#include <algorithm>
#define INF 12345678987654321LL
using namespace std;
typedef long long ll;
void solve(vector<ll>& address, ll N, ll C, ll M) {
//dp[count][x] = x위치에 count번째 사업장을 놓을때 최소 cost
//ret = min(dp[count][x], ret), ret init = inf
//dp[count][x] = min(dp[count - 1][k < x] + C * summation(|x - update_loc|)
// - C * summation(|k - update_loc|) + m, dp[count][x])
//dp init = inf
//dp[1][x'] : for every x', dp[1][x'] = C * summation(|x' - loc|) + m
//5000 * 5000 vector -> x는 N에서 유효한 좌표만 있으면 되기 때문에 최대 ~ 100MB
ll ret = 12345678987654321LL;
int retCnt = 1;
sort(address.begin(), address.end());
vector<ll> cpy(address);
cpy.erase(unique(cpy.begin(), cpy.end()), cpy.end());
vector<vector<ll>> dp(N + 1, vector<ll>(N + 1, INF));
for(int i = 0; i < (int)cpy.size(); ++i) {
ll s = 0;
for(auto& element : address) s += abs(cpy[i] - element);
dp[1][cpy[i]] = C * s + M;
ret = min(ret, dp[1][cpy[i]]);
}
for(int count = 2; count <= N; ++count) {
for(int loc = 0; loc < cpy.size(); ++loc) {
for(int k = 0; k < loc; ++k) {
ll sCur = 0, sLast = 0;
for(auto& element : address) {
if(abs(element - cpy[k]) > abs(element - cpy[loc])) {
sCur += abs(cpy[loc] - element);
sLast += abs(cpy[k] - element);
}
}
dp[count][cpy[loc]] = min(dp[count][cpy[loc]],
dp[count - 1][cpy[k]] + C * sCur - C * sLast + M);
if(dp[count][cpy[loc]] < ret) {
ret = dp[count][cpy[loc]];
retCnt = count;
}
}
}
}
cout << ret << " " << retCnt;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
ll N; cin >> N;
vector<ll> address(N);
for(int i = 0; i < N; ++i) cin >> address[i];
ll C, M; cin >> C >> M;
solve(address, N, C, M);
return 0;
}
F번 : 피자는 나눌 수록 커지잖아요 / BOJ 17946
Tier : Bronze II
설명 보기
좀 황당한 문제랄까? 모든 테케에 대해 1만 출력하면 그게 답이다. 왜냐면, 자를때마다 최대 3개의 조각이 더 생기는데 이게 4개 이상부터는 줘야하는 갯수보다 작아지니까 특정횟수 이상부터는 음수값이 나온다. 여기선 최대로 먹을 수 있는 피자조각수라 했는데, 이걸 계산해보면 1보다 커질 수 없음을 쉽게 알 수 있다.
코드 보기
#include <iostream>
using namespace std;
int main() {
int N; cin >> N;
while(N --> 0) {
int K; cin >> K;
cout << 1 << '\n';
}
return 0;
}
G번 : 투튜브 / BOJ 17954
Tier : Gold I
설명 보기
constructive proof 문제다. greedy하게 접근해보자면, 매 순간순간마다 빼낼 수 있는 원소중에서 가장 큰 원소를 꺼내도록 하면 부패도의 누적이 최소가 된다. 2N, 2N-1, 2N-2, 이 3개의 숫자는 가장 처음 빼내질 수 없는 수라는게 자명하다. 따라서, 2N-3부터 꺼내질 수 있다. 그렇게 하기 위해선 2N ~ 2N-2의 수가 모서리에 각각 하나씩 있어야 함을 알 수 있다. 그 다음으론 2N-4부터 쭉 빼낼 수 있도록 배치해주면 남은 수부터 큰 순으로 일렬로 배열되어야 한다는 사실을 깨달을 수 있다. 그럼 한 행에 단 하나의 원소가 남는 때가 오는데 그 때, 남은 원소가 2N, 2N-1, 2N-2중 하나가 된다. 큰수를 먼저 빼는게 유리하기에.. 그 행에 남은 한 원소는 2N-2이 되어야 부패도가 최소가 될 수 있음을 어렵지 않게 관찰할 수 있다. 그런 다음엔 순서대로 2N-1이 빠지고, 2N을 제외하고 나머지 원소들이 다 빠진후 2N이 빠지게 되어 부패도가 최소가 된다. 즉, 다음 그림처럼 원소를 배치하면 된다는 얘기이다.
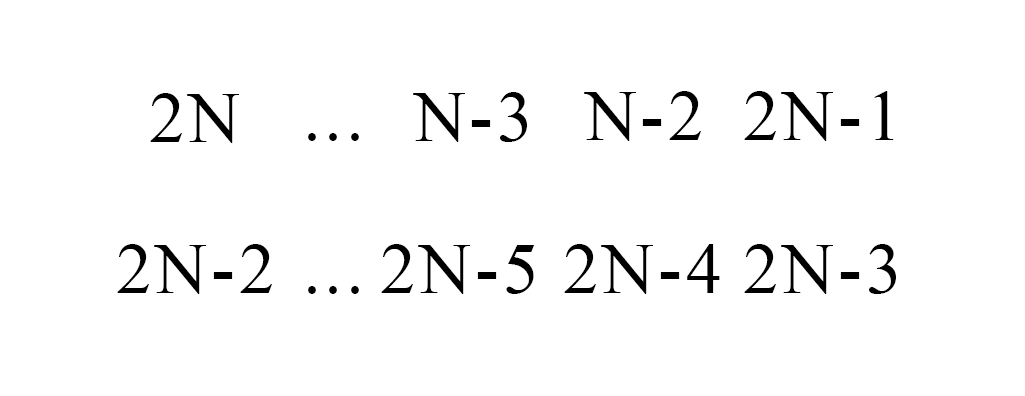
코드가 다소 지저분하긴 하나, 대충 요런식으로 배치를 구성한 뒤 직접 부패도를 계산해서 부패도와 함께 배치를 출력해주면 AC.
코드 보기
#include <iostream>
#include <vector>
using namespace std;
typedef long long ll;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int N; cin >> N;
vector<vector<int>> apple(2, vector<int>(N));
if(N != 1) {
apple[0][0] = 2 * N;
apple[0][N - 1] = 2 * N - 1;
apple[1][0] = 2 * N - 2;
apple[1][N - 1] = 2 * N - 3;
int col = N - 2;
for(int i = 2 * N - 4; i > N - 2; --i) apple[1][col--] = i;
col = N - 2;
for(int i = N - 2; i > 0; --i) apple[0][col--] = i;
ll time = 1;
ll s = N * (2 * N + 1);
ll ret = 0;
ll now = 2 * N - 3;
for(int i = 0; i < N - 1; ++i) {
s -= now--;
ret += s * time++;
}
now = 2 * N - 2;
s -= now;
ret += s * time++;
now = 2 * N - 1;
s -= now;
ret += s * time++;
now = N - 2;
for(int i = 0; i < N - 2; ++i) {
s -= now--;
ret += s * time++;
}
cout << ret << '\n';
for(int i = 0; i < 2; ++i) {
for(int j = 0; j < N; ++j) {
cout << apple[i][j] << ' ';
}
cout << '\n';
}
}
else {
cout << 2 << '\n';
cout << 1 << '\n' << 2;
}
return 0;
}
H번 : 상남자 곽철용 / BOJ 17947
Tier : Gold I
설명 보기
문제 핵심 아이디어는 모듈러를 취했기에 그룹으로 각각의 수를 나눌 수 있다는 점이다. mod K에 대해 수를 모아보면, 각각 0 ~ K-1사이의 값을 가지게 된다. 곽철용이 뽑은 수가 A, B이고 점수를 \(\scriptsize score = \|A mod K - B mod K\|\) 라 할 수 있으니, 다른 사람들이 가능한 점수들 중에 score + 1 부터는 순서쌍이 몇개나 존재할 수 있는지만 알면 된다. score + 1부터 시작해서 K - 1까지 쭉 훑으면서 해당 카드들에 대응하는 카드가 몇개 있는지 세주고, 그 쌍이 M - 1개를 초과하면 M - 1명 모두 곽철용을 이길 수 있다는 의미이니, 그때는 값을 M - 1로 바꾸어 주면 해결. 해보면 알겠지만 이 쌍을 세는 과정이 그리 쉽지가 않아서.. 나도 다 풀어놓고 구현을 한참동안이나 계속 고쳐서 겨우 AC를 받아냈다. 다른 사람들 풀이를 보니 two-pointer를 사용해 하나씩 지우는 풀이가 많이 보이는듯 했다. 뭐 난 그렇게 풀진 않았지만, 여튼 그런방법으로도 순서쌍을 셀 수 있다.
코드 보기
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
int main() {
int N, M, K; cin >> N >> M >> K;
vector<int> modSeq(K);
for(int i = 1; i <= 4 * N; ++i) modSeq[i % K]++;
for(int i = 0; i < M; ++i) {
int a, b; cin >> a >> b;
modSeq[a % K]--; modSeq[b % K]--;
}
int A, B; cin >> A >> B;
modSeq[A % K]--; modSeq[B % K]--;
int scr = abs(A % K - B % K);
int cnt = 0;
int s = 0;
for(int i = scr + 1; i < K; ++i) {
s += modSeq[i - scr - 1];
cnt += min(s, modSeq[i]);
s -= min(s, modSeq[i]);
}
if(cnt >= M) cnt = M - 1;
cout << cnt;
return 0;
}
I번 : 통학의 신 / BOJ 17945
Tier : Bronze III
설명 보기
“근의 공식을 알고있니?” 수준의 문제다. 근의 공식으로 근을 구해서 같으면 하나만 출력, 아님 둘 다 출력하면 AC.
코드 보기
#include <iostream>
#include <cmath>
using namespace std;
int main() {
int A, B; cin >> A >> B;
int x1 = (double)(-A) - sqrt(A * A - B);
int x2 = (double)(-A) + sqrt(A * A - B);
if(x1 == x2) cout << x1;
else cout << x1 << " " << x2;
return 0;
}
J번 : 스노우볼 / BOJ 17950
Tier : Bronze II
설명 보기
1 cm 간격으로 x배되니, 한 줄 처리할때마다 x배 시켜서 답에 더하고 출력하면 AC.
코드 보기
#include <iostream>
#include <vector>
using namespace std;
typedef long long ll;
const ll MOD = 1e9 + 7;
int main() {
ll H, x; cin >> H >> x;
ll ret = 0;
ll x_0 = x;
for(int i = 0; i < H; ++i) {
ll k; cin >> k;
ret += (k % MOD) * (x % MOD);
x *= x_0;
ret %= MOD;
x %= MOD;
}
cout << ret % MOD;
}
K번 : 디저트 / BOJ 17953
Tier : Gold V
설명 보기
2차원 DP로 해결할 수 있는 문제다. n번째 날의 최대 만족감은 n - 1번째 날의 최대 만족감에 의해 결정되기 때문에, 그렇게 부분문제로 나누어서 풀 수 있고, 이걸 점화식을 잘 만들면 \(\scriptsize O(nm ^ {2})\)에 풀 수 있다.
\(\scriptsize sat(day, type_x) = "day에 type_x를 먹었을때, 최대 만족감의 크기"\)라고 정의하자.
그러면, \(\scriptsize sat(day, type_x) = max(sat(day, type_x), value(day - 1, type_y) + sat(day - 1, type_y))\) 임을 알 수 있다. 이때 \(\scriptsize type_x = type_y\)이면 \(\scriptsize value /= 2\)해주면 된다. 이때 답은 \(\scriptsize max(sat(N, type_k))\)가 됨을 알 수 있다. 이걸 찾아서 출력하면 AC.
코드 보기
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int N, M; cin >> N >> M;
vector<vector<int>> dp(N, vector<int>(M));
vector<vector<int>> seq(N, vector<int>(M));
for(int i = 0; i < M; ++i) {
for(int j = 0; j < N; ++j) {
cin >> seq[j][i];
}
}
for(int i = 0; i < M; ++i) dp[0][i] = seq[0][i];
for(int i = 1; i < N; ++i) {
for(int j = 0; j < M; ++j) {
for(int k = 0; k < M; ++k) {
if(j == k) dp[i][j] = max(dp[i - 1][k] + seq[i][j] / 2, dp[i][j]);
else dp[i][j] = max(dp[i - 1][k] + seq[i][j], dp[i][j]);
}
}
}
cout << *max_element(dp[N - 1].begin(), dp[N - 1].end());
}
짧은 후기
이 셋에서 나한테 가장 개인적으로 어려웠던 문제는 아직까지도 못푼 “뜨끈한 돼지국밥“이다. 난 DP를 너무 못하는데,, 이 문젠 DP만으로 플래티넘을 찍은 문제라.. 어쩌면 지금의 나는 풀 수 없을지도 모르겠다 ㅋㅋ 가장 좋았던 문제는 투튜브라고 생각한다. 논리적인 사고만으로도 재밌게 풀 수 있던 문제라 꽤 괜찮았다고 생각한다. 윽.. 올해 대회에서 뭐라도 받을 수 있으면 좋을듯ㅎ