[DBMS] 06. Aggregation & Group By
31 Aug 2023- 한양대학교 컴퓨터소프트웨어학부 정형수 교수님의 2022년도 데이터베이스시스템및응용 강의를 듣고 정리한 내용임을 밝힙니다.
- 내용에 오류가 있을 수 있으며, 발견 시 댓글로 알려주시면 감사하겠습니다.
6. Aggregation & Group By
- 집계 함수와 그룹화에 대해 알아보자.
Aggregation
집계 함수는 어떤 테이블의 데이터를 가지고 하나의 값을 만들어내는 함수를 의미한다. 어떤 테이블의 레코드 수를 세고 싶으면 COUNT를 사용할 수 있고, 합을 나타내려면 SUM을 사용하면 된다. 이외에도 AVG, MAX, MIN 등의 여러 집계 함수들이 존재한다.
COUNT
- 테이블의 레코드 수를 센다.
SELECT COUNT(*)
FROM A;
별표는 모든 칼럼을 의미한다. 따라서 위의 쿼리는 A 테이블의 레코드 수를 세는 것이다. 오호, 그럼 아무 칼럼이나 넣어도 같은 값이 아닌가? 하는 생각을 할 수 있는데 특정 칼럼에 NULL이 존재하면 해당 레코드는 제외하고 센다. 따라서, COUNT(*)와 COUNT(칼럼)은 다른 결과를 보일 수 있다. COUNT가 적용되는 시점은 5장에서 얘기했듯 WHERE 절이 적용된 이후이다. 따라서, 어떤 쿼리의 결과에서 COUNT를 센다고 생각하면 된다.
SUM
- 테이블의 특정 칼럼의 합을 구한다.
SELECT SUM(column)
FROM A;
COUNT 이외에는 모두 단일 칼럼에만 적용된다. 모든 레코드의 해당 칼럼 값을 더해서 반환한다.
AVG
- 테이블의 특정 칼럼의 평균을 구한다.
SELECT AVG(column)
FROM A;
MAX
- 테이블의 특정 칼럼의 최댓값을 구한다.
SELECT MAX(column)
FROM A;
MIN
- 테이블의 특정 칼럼의 최솟값을 구한다.
SELECT MIN(column)
FROM A;
Group By
어떤 제품의 개수를 그룹별로 알고 싶을 때 어떻게 해야할까? 테이블을 Product(name, date) 라고 하자. 각각 제품 이름과 제품 생산 일자이다. name별로 개수를 알고 싶다고 생각해보자. 이런 상황에서 Group by를 사용할 수 있다.
SELECT name, COUNT(*)
FROM Product
GROUP BY name;
음.. 뭐가 어떻게 묶이는 건지 잘 모르겠다. 다음 예제를 보자.
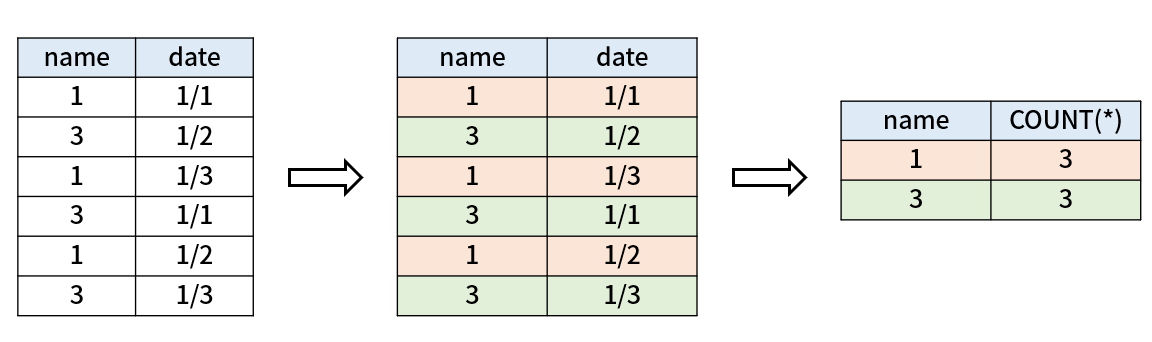
name이 같은 레코드들을 묶어서 값을 한 번에 나타내는 것으로 이해할 수 있다. 즉, GROUP BY는 특정 칼럼을 기준으로 레코드들을 묶는 것이다. 두번째 과정에서 GROUP BY로 그룹이 생기고 마지막에 projection이 적용되며 count 결과를 얻게 된다.
Having
Aggregate에 제약을 거는 것으로 간단하게 설명할 수 있다. 만약 count가 2 이상인 것만 보고 싶다면 다음과 같이 하면 된다.
SELECT name, COUNT(*)
FROM Product
GROUP BY name
HAVING COUNT(*) >= 2;
즉, GROUP BY 이후에 HAVING이 적용된다고 생각할 수 있다. 이후 projection이 적용된다.
쿼리 실행 순서?
실제 실행 순서는 이와 다를 수 있지만, 의미상 실행 순서는 다음과 같다. FROM -> WHERE -> GROUP BY -> HAVING -> SELECT Projection이 마지막에 적용되는 것을 생각하면 생각보다 헷갈리지 않으니 참고하자.
요약
- 집계 함수는 테이블의 레코드를 가지고 하나의 값을 만들어내는 함수이다.
- GROUP BY는 특정 칼럼을 기준으로 레코드들을 묶는 것이다.
- GROUP BY 이후에 HAVING이 적용된다고 생각할 수 있다. 이후 projection이 적용된다.
- 실행 순서는 FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 이다.